
Provision.io uses AI to identify what type of French cheese you are eating. Just take a picture and go!
Computer vision use cases are hot topics and a frequent one in the AI world. They often are impressive. Seeing AI naming or classifying an image truly shows how far the field has come in the last ten years.
That said, there are few real world use cases deployed. With the exception of the standard cat picture found everywhere, building your own Computer vision model from scratch is expensive and quite difficult without the skill and knowledge of a skilled data scientist.
Here at Provision.io we tried to build a model trained to recognize french cheese, something that has never been done before, but with one major constraint. We limited our analysis to 5 days.
Did we succeed?
Yes. Let’s first start with some more general analysis of computer vision use cases.
Section 1: What is a computer vision use case?
Computer Vision is one of the areas that has benefited the most from progress in AI. It encompasses four main types of problem, ranging from the least amount of human intervention to the most :
- image generation: AI learns to generate images that look like a man made image
- image clustering: AI is able to group different images by similarity without human intervention
- image classification: AI learns to put a label on an image (a number, a tag, a sentiment)
- Object detection and segmentation: inside an image, draw a bounding box or a detailed contour of an object
Image generation and clustering share the same underlying techniques. Images are encoded with mathematical vectors such that vectors for similar images have a “small distance” between them and images can be rebuilt from its vector. The following is the DCGan Architecture and its variant, which is behind all the wow! demos seen on the Internet. Some examples are the famous Dall-E, GauGAN or thispersonndoesnotexist.
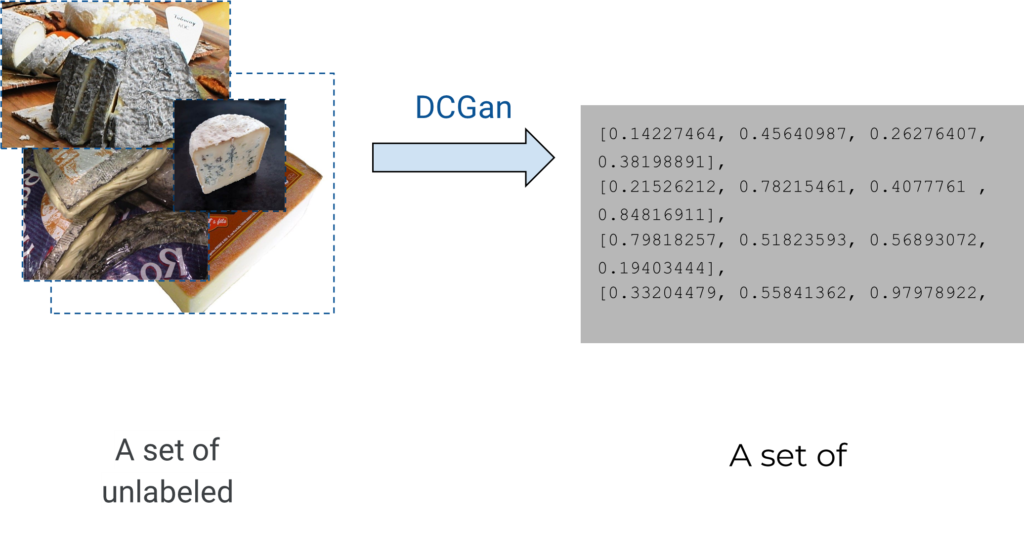
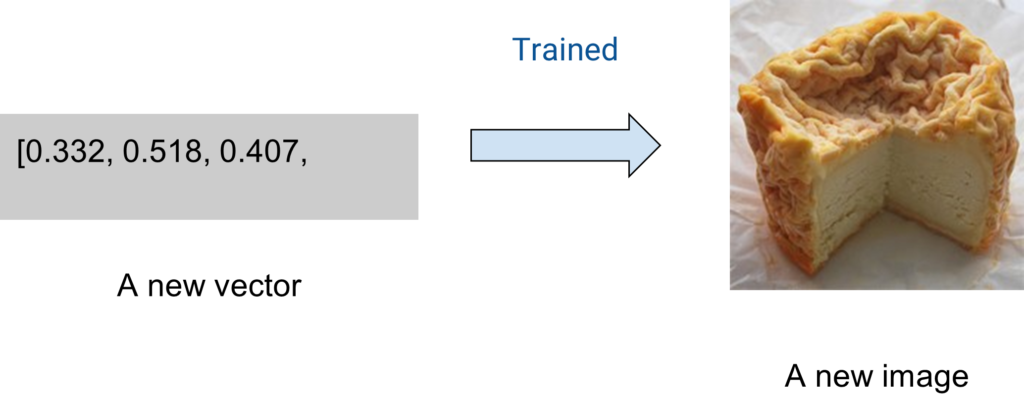
As long as you have trained a DCGan, you can generate a new image by putting a new vector into it.
And common clustering techniques can be applied on the image’s vectors, as they are standard mathematical vectors upon which a distance can be built, representing similarities.
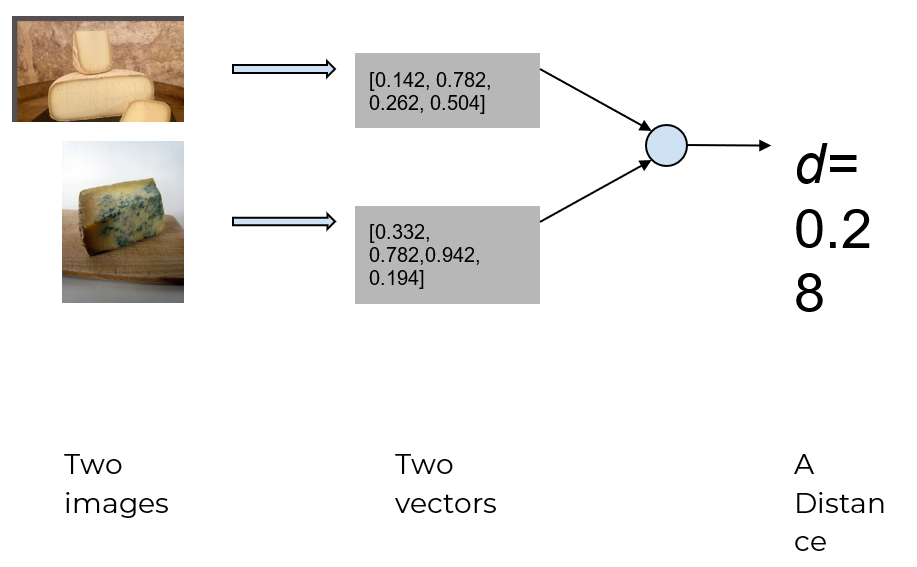
For each couple of images we can build a distance
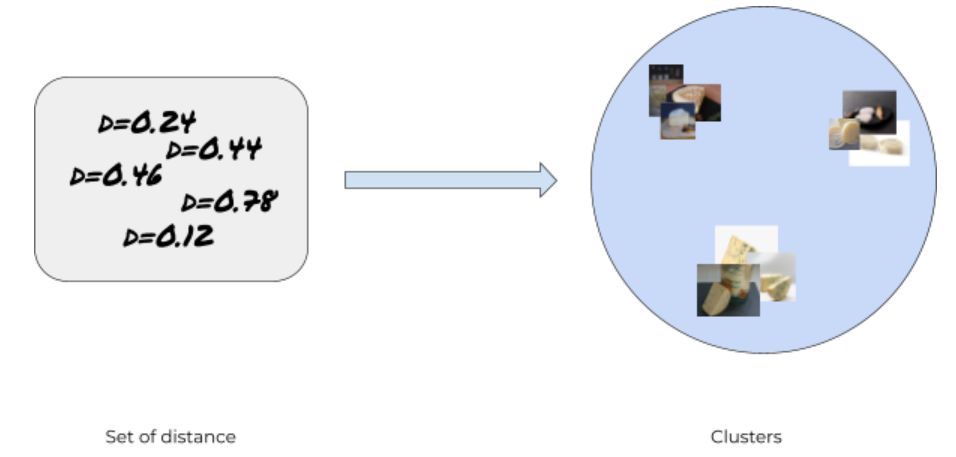
And from a distance matrix, we can build clusters
From Vectors and clusters, you may start to build classification:
- either in a semi-supervised way by putting manual labels on each cluster if they look good. But, be aware that your cluster may not be exactly your label (a typical example is a cluster built on image characteristics like lighting and colors or even the type of background)
- put a class on your list of vectors. Thus, you can go back to a tabular use case where your classic model tries to find a relation between a list of float and a target class
Of course you may go the traditional way with a CNN (Convolutional Neural Network) where the target is your class but using a Gan brings the benefit of getting an embedded vector for each of your images that can be stored for later usage (typically charts of images similarity).
Another standard usage of Computer Vision is Object Detector and segmentation. Inside of an image, find the bounding box or contour of one or more objects, and label (classify) this object

Detection (left) and segmentation ( right )
Section 2: Where do the costs come from?
Each of these use cases can obviously earn you some gain, typically by automating a human task (e.g. executing it faster or cheaper ) or by being better at it ( for example detecting more of some object or sooner )
Computing gain is a topic for another article but let’s see where expenses come from during a Computer Vision use case.
Image Acquisition
AI is good but still not as good as humans to learn something new.
For understanding an image, standard Computer vision still needs a lot of images (we are talking about tens of thousand images for a use case).
It sometimes depends on the problem. For example, detecting a pool, a blue rectangle in a forest, round green stuff, is easier than trying to classify a benign mole from a malignant one. But, it often comes with a cost.
There are 3 way to acquire images :
- You already have them for historical reasons. For example you work for an insurance company and have a lot of damaged car photos.
- Scraping them on the web by using some API. Typically, Google charges $5 for 1000 satellite image taken from its api
- Make your own database by recruiting humans and let them take photos of the object you want to tackle
Scraping images from the web is the cheapest. You can quickly access a few thousands of images for free. Be cautious, images from the web could be unrelated to your objective, or bring lighting quality that differ from your real use case (sometimes best, sometimes worst ).
As an alternative, build your own database by allowing others to take photos in true real condition. This avoids having too much difference between the train set and the production usage, as you can tell your photographer to take images in the same condition for future usage. This is very expensive. Expect to only receive one or two hundred image a day for each people working on acquiring images
The smartest way is obviously a mix of several methods. Start a model with the cheapest method, for example scrape a hundred images and then use humans to label them correctly or update the model with the obvious errors.
You should not expect to have the perfect dataset at the first model. However, building a first cheap model allows your dev team or alpha tester to use it on real images and give feedback.
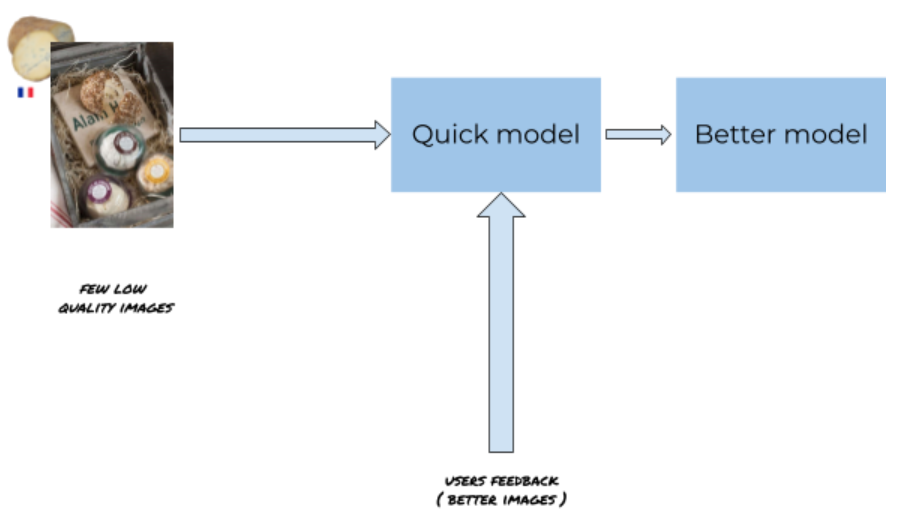
The less expensive way to get a model good enough is to start with the higher complexity modeling (here an object detector) on a few images, then generate some predictions and get new images and corrections from the user to improve the initial model.
It will always be better to train the model on images sent from real usage rather than training on generic images, like the ones found on the internet.
Method | nb image expected | image quality ( related to the problem ) | cost by image | Total acquisition cost |
you own data | > 10000 | very good | almost 0 | almost 0 |
scraping | ~10000 | bad | $~0.005 | ~100$ |
human acquisition (photo ) | ~1000 | very good | $~0.5 | ~500$ |
Obviously, the best outcome is to already have images in your SI but we are dealing with the case you are starting a new modeling from scratch.
Image Labeling
In most computer-vision use cases, this could be the most expensive step. Depending on your use case, you can go from no labeling, and thus no cost, to very accurate labeling that is quite costly.
Zero – labels: Image generation
If you want to generate an image that looks like some other image from your dataset, you never need to label your images. Just throw the most pertinent image in a folder and run a DCGAN, or its variation, as the “A” in DCGAN implies – use an Adversarial neural network to decide if your generated image is good or not.
Yet, expect your training cost to be very high as good image generation with high definition often needs several days of training on racks of GPUs.
Even if you have no labeling costs, do not forget that this use case is the most expensive in compute cost for training
Few labels: Clustering
Sometimes called semi-supervised. When clustering your image, you ask your algorithm to split your image “the best it can”.
By doing this the images will be :
- grouped by similarity
- moved away from each other the more dissimilar they are
- assigned a “class” (a cluster number)
The results will be that you have quite good output. All your images are pre-tagged and all you have to do is put labels on clusters instead of labeling each image.
I need to point out that unless you get lucky, this rarely works as the standard clustering algorithm will split the image along the characteristics and in most cases for images, it will be something like light conditions or background colors.
For example for cheezam, when we submitted a set of 1000 images, they were split into about 6 clusters that were :
- the orange cheese ( mimolette, langres, etc.)
- the white cheeses ( goat cheeses in most cases )
- the cheese on white plate ( aka a big round white circle is on the image )
- the cheeses on black background
- …

The clusters are perfectly valid. Image of cheese on a black background and image of orange cheese
Thus, in order to get a business related model, in most cases, you should apply some label to teach the machine what you expect (or which features of your image you want to put an emphasis on).
Labeling: Image Classification
To train a model to recognize Fromage de Langre from Mimolette, you need some human in the loop that puts a “mimolette” label on mimolettes images. With high complexity classification like splitting Brie de Meaux from Camembert, this can take up to 3s an image, meaning a rate of about 1000 image/hour , or something like $25 for 1000 images ( $250 for 10000 images ).
The other way is directly label images while acquiring them :
- either by using scraper and labeling images while scraping them (for example, make an image search with the term “fromage mimolette” and put the result in the mimolette folder
- or by using a tool that enabled labeling while acquiring images
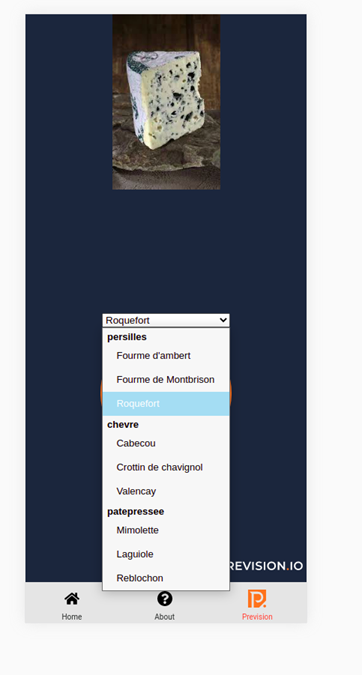
The behind the scene Cheezam label tool: snap your cheeses with a smartphone and send them labeled. Images are then sent to storage
With this kind of tool, you can expect to acquire 250 images a day by person with its label putting the cost of acquiring + labeling to about $1 an image.
In order to kickstart a model, you probably need 200 images of each class (depending on separability of class ) so a typical multi classification with 5 classes needs 1000 images or $1,000 to get images labeled.
Bounding box : Object Detector
The next stage of computer vision is more difficult and costly. Object detection tries to number and locate an object on a photo by putting a bounding box around it.
It means that :
- there could be more than one object on each image
- you need to draw one rectangle (bounding box) or more on each image, which is a very tedious task
The benefit of a bounding box is that your model can tell you if there are several objects of different kinds on an image and count them. This avoids just classifying the images, which is exactly what we want to do with Cheezam.
For building the Cheezam dataset, we managed to draw about 500 boxes a day using https://www.makesense.ai/. This is free, online and open source or for labeling https://blog.roboflow.com/labelimg/ which requires some computer skill to set up.
This drawing cost adds to the image acquisition and labeling as when drawing your box you still must add a label. We found it very efficient to use only one generic label when drawing a bounding box (“cheese”) and splitting the process of putting the right label from the process of drawing the box.
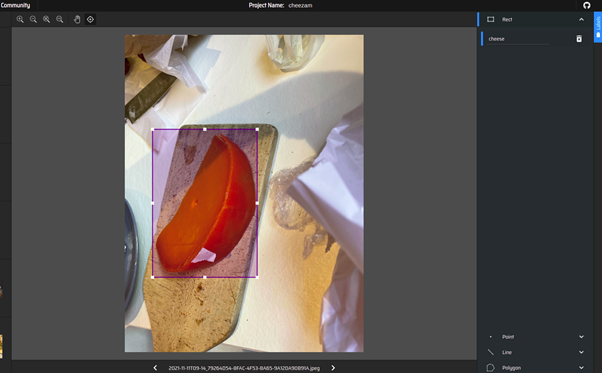
Box bounding my mimolette
High complexity labeling: Object Segmentation
Object segmentation is similar to Object Detection but instead of a bounding box, you draw a polygon that perfectly fits your object.
The needs of human manual labor for this kind of task is huge, ten times the time for a “simple” object detector with bounding boxes.
We tried it on a small dataset of 200 images for Cheezam and the performances, counting the cheese and finding the right class, were not significantly improved.
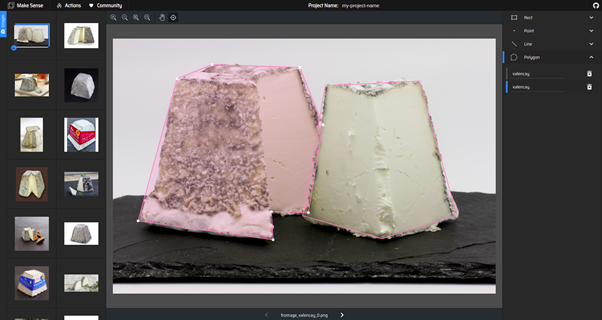
Detouring my valencay
This kind of task happens when you need to compute the size or area of an object, or for some very specific use case which needs the exact shape of the object.
You should always compute your expected gain when starting this kind of project to evaluate the cost/benefit.
Problem | Time | Cost | benefit |
Generation | 0 | 0 | you can generate new image |
Cluusterization | 0 | half a day | serve as basis for human labelization (semi supervised) |
Classification | 10000 images a day | $25 / 1000 | train a model with business oriented class |
Object detection | 500 images day | $500/1000 | many class on each images, counting the object |
Object segmentation | 50 images a day | $50000/1000 | compute the size or area of object on image |
Labeling cost
Training
The training cost could be split into two parts:
- image generation which is a very heavy process and which needs several hours of high-end GPUs
- the other task, which takes around 10 hours for training a model on ~1000 images
The first costs several thousands of dollars.
The second costs about one hundred dollars.
Of course it greatly depends on the performance you expect so as a rule of thumb, count $100 for each 1000 images into your dataset, with iteration and optimization.
Cheezam was a dataset of 3000 images and we ran several trainings using a total of 110 hours of compute for a total $283 using Provision.io on GCP.
Cheezam, The most Efficient way: a hybrid approach of human and AI
Ok, so finally, what was the best way?
With trial and error, we successfully achieved a very efficient method that we applied on cheezam. Here’s what that looks like.
1 – Acquire 500 photos of cheese on the web with their label.
Cost: 1 hour of work (scraping script)
2 – Draw bounding box around each photo with only one label (quicker)
Cost: 3 hours of work
3 – Train a model on it
Cost: 20 hours of computing
4 – Deploy the model and allow a co-worker to use it in a real world condition (real light, smartphone lens quality, backgrounds of all shapes, etc ) and letting them send a label with their photo.
Cost : 2 days of (accumulated) work
The real ground breaking idea was to let the first model draw the bounding box because humans are too slow. Then to keep the human mind for applying the labels.
5 – Retrain a model with the bounding box drawn by the first model on a real world image and with a label from the human
Cost: 100 hours of computing
6 – And finally, put that model into production.
Cost: 10 minutes
The main issue of this method was that we asked co-workers not to take too many images at once, otherwise we would have needed a tool to pinpoint the cheese on each image, which was tedious with a smartphone.
Letting the model focus on bounding boxes while humans were in charge of putting labels while acquiring images was a good way to benefit from the best of both worlds.
If you are interested in trying the application. You can find Cheezam on its dedicated page https://cheezam.fr.
A part of the dataset is available on our public storage (and its labels).
It is currently trained on a family of cheese instead of a specific name. Cheezam version 2.0 is in the pipeline and our team is working hard to get a lot of images of Cabecou and Rocamadour. Enjoy!



