
What are these two concepts and their main differences?
This blog post series will consist of two blogs:
- The first blog post will explain interpretability and explainability, the differences between them, and introduce concepts that will be explored in the second
- The second blog post will show how the io platform provides interpretability and explainability solutions (data explanation, model explainability, global explainability and local explainability).
Introduction
Nowadays, Artificial Intelligence (AI) is available in our everyday life. However, even with unprecedented progress, a major obstacle to the use of AI-based systems is that they often lack transparency. Indeed, the complexity of these systems allows powerful predictions, but it cannot be explained directly. In this article, we will try to answer the questions below :
- What is interpretability in machine learning ?
- What is explainability in machine learning ?
- What are the main differences between interpretability and explainability in machine learning ?
- Why might a model need to be interpretable and/or explainable ?
- What are the available tools to explain a machine learning model, predictions/decisions ?
What is interpretability in machine learning ?
An interpretable model can be understood by a human on its own, without any other aids or techniques.
We can understand how these models make predictions by looking only at the model summary and / or coefficients of the equation in the case of linear regression.
Examples of interpretable models: decision trees and linear regression. In Provision.io, we named these models: Simple Models.
What is explainability in machine learning ?
To help understand what Explainable Machine Learning is, you can think of a ML model as a function. The data features are the input and the predictions are the output. When a model is too complicated (like neural networks often called black-box models), to be understood directly by a human, the data scientist uses explainable complementary solutions to approach this complex model either through approximate models, or through graphic analysis. In other words, we need an additional method/technique to be able to peer into the black-box and understand how the model works.
An example of such a model would be a Random Forest, Deep Learning model or a
Gradient Boosting or any ensemble models.
For example, a Random Forest is made up of many Decision Trees where the predictions of all the individual trees are taken into account when making the final prediction. To understand how a Random Forest works, we have to simultaneously understand how all of the individual trees work. Even with a small number of trees, this would not be possible.
Posteriori solutions are used to understand the link between the inputs and the output(s).
What are the main differences between interpretability and explainability in machine learning?
Disclaimer: It is a controversial subject, not everyone agrees on this distinction. For some, the two terms “explainability” and “interpretability” are interchangeable. For others, and this is how I see it, there are several distinctions between these two terms.
Machine Learning algorithms, no matter how well they perform, often cannot provide explanations for their predictions in terms that humans can easily understand. The characteristics from which they draw conclusions can be so numerous, and their calculations so complex, that data scientists may find it impossible to establish exactly why an algorithm produces these probabilities / decisions. However, it is possible to determine how a machine learning algorithm came to its conclusions.
This ability, how a machine learning algorithm came to its conclusions, is also called interpretability. Interpretability is a very active area of investigation among AI researchers in academia and industry.
It differs slightly from explainability, trying to answer why an algorithm produces the responses it produces. Explainability can reveal the causes and effects of changes within a model, even if the inner workings of the model remain a mystery.
How = Interpretability Why = Explainability
We say that something is interpretable if it can be understood. Keeping that in mind, we say a model is interpretable if it can be understood by humans on their own. We can look at a model’s parameters or a model’s summary and understand exactly why it made a certain prediction or decision. From my point of view, interpretable models include decision trees and linear regression.
However, an explainable model does not provide its own explanation. On their own, these models are too complicated to be understood by humans and they require additional techniques to understand how they make predictions.
Interpretability has to do with how accurate a machine learning model can associate a cause to an effect. Explainability has to do with the ability of the parameters, often hidden in Deep Neural Networks, to justify the results.
A machine learning model is interpretable if we can fundamentally understand how it came to a specific decision. A model is explainable if we can understand how a specific node in a complex model technically influences the output.
To end this comparative paragraph, I will quote Gartner which distinguishes the two notions such as :
- Model Interpretability aims to understand the output (prediction or decision),
- Model Explainability aims to understand how the model
Why should a model be interpretable and/or explainable ?
Interpretability is crucial for several reasons:
- If data scientists do not understand how a model works, they may have difficulty transferring the learning into a larger knowledge
- Interpretability is essential to guard against built-in biases or to debug an
- As algorithms play an increasingly important role in society, understanding precisely how they find their answers will become more and more
- In heavily regulated industries like banking, insurance, and healthcare, it is important to be able to understand the factors that contribute to likely outcomes in order to comply with regulation and industry best
- Data scientists sometimes need to compensate for incomplete interpretability through judgment, experience, observation, monitoring and diligent risk management, as well as a deep understanding of the datasets they use. However, several methods exist to improve the degree of interpretability in machine learning models, regardless of their This article summarizes several of the most common among them, including their relative advantages and disadvantages.
Explainability is important but not always necessary. A machine learning engineer can build a model without having to consider the model’s explainability. It is an extra step in the building process.
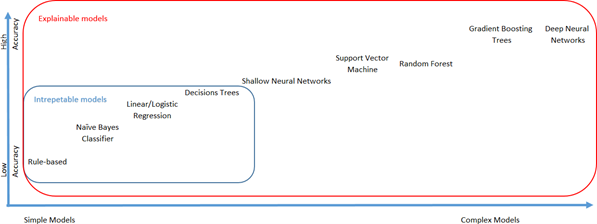
Trade-off between model complexity and predictive performance, split between interpretable models and models requiring post processing to be explained
Interpretability of a machine learning model is usually related to the model’s complexity. Indeed, as the complexity of a model increases, it becomes less interpretable. Therefore, a tradeoff between performance and complexity of a model should be considered (see the figure above).
Among the machine learning family methods, four are known to be interpretable: rule-based, naive Bayes classifiers, linear/logistic regression and decision trees. These models can be used in order to explain complex models such as deep neural networks.
It should be noted that any machine learning model can be explained by using appropriate techniques. In the following section, four of the main techniques are presented.
What are the available tools to explain a machine learning model, predictions/decisions?
I present below four techniques to improve the understanding of complex models:
- Model surrogate
- Partial dependence plots
- Permutation feature importance
- Individual Conditional Expectation
Model surrogate
A surrogate model is an interpretable model (such as a decision tree or linear model) that is trained to approximate the predictions of a complex model. We can better understand the model to be explained by interpreting the surrogate model’s decisions.
Advantages: You learn what the complex model thinks is important by approximating it. It is easy to measure: it’s clear how well the interpretable model performs in approximating the original model through the R-squared metric for regression or AUC for classification. This approach is intuitive.
Limitations: A linear model may not approximate a complex model as linear models are not able to capture non-linear relationships between the input variables and the output.
You draw conclusions about the original model and not the actual data, as you use the complex model predictions as labels without seeing the ground truth.
Even if you do approximate the complex model well, the explainability of the “interpretable” model may not sufficiently represent what the complex model has learned.
More details about surrogate models can be found here.
Partial Dependence Plots
A partial dependence plot shows the marginal effect of a feature on the outcome of a ML model.
Partial dependence works by marginalizing the machine learning model output over the distribution of the features we are not interested in. The partial dependence function shows the relationship between the features we are interested in and the predicted outcome. Partial dependence plots help to understand how varying a specific feature influences model predictions.
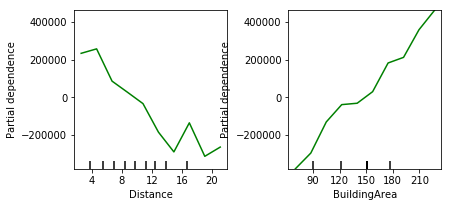
Example of Partial Dependence Plot
These graphs show the evolution of the sale price of a house according to two variables: distance and building area:
- the greater the distance, the lower the selling price will
- the bigger the building area, the more the sale price will go
Advantages: Partial Dependence Plots are highly intuitive. The partial dependence function for a given value of a variable represents the average prediction if we have all data points that assume that feature value.
Limitations: You can really model only a maximum of two features using the partial dependence function.
If you want to know more about Partial Dependence Plot, follow this tutorial on Kaggle.
Permutation feature importance
Permutation feature importance is a way to measure the importance of a feature by calculating the change in a model’s prediction error after permuting the feature. A feature is “important” if permuting its values increases the model error, and “unimportant” if permuting the values leaves the model error unchanged.
Advantages: Feature importance is just how much the error increases when a feature is distorted. This is easy to explain and visualize. Permutation feature importance provides global insight into the model’s behavior. It does not require training a new model or retraining an existing model, simply shuffling features around.
Limitations: If features are correlated, you can get unrealistic samples after permuting features, hence biasing the outcome. Adding a correlated feature to your model can decrease the importance of another feature.
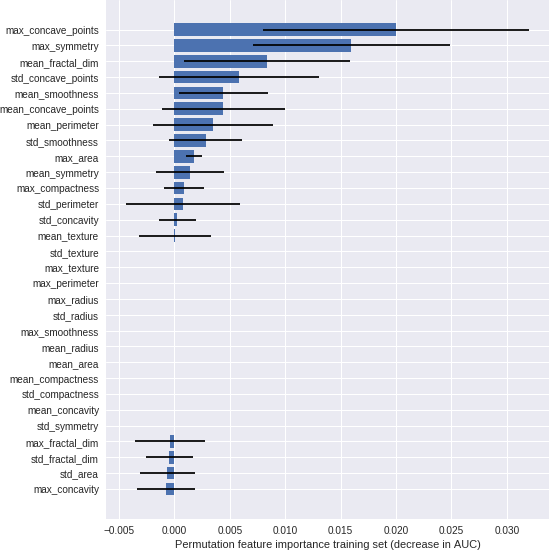
Example of Permutation Feature Importance
If you want to know more about Permutation Feature Importance, follow this tutorial on Kaggle.
Individual Conditional Expectation
Individual Conditional Expectation (ICE) plots display one line per data point. It produces a plot that shows how the model’s prediction for a data point changes as a feature varies across all data points in a set.
Advantages: Like PDP plots, ICE plots are very intuitive to understand. ICE plots can uncover heterogeneous relationships better than PDP plots can
Limitations: ICE curves can only display one feature at a time. The plots generated with this method can be hard to read and overcrowded.
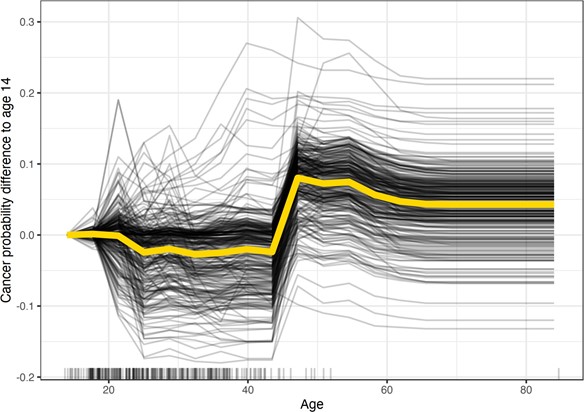
Example of Individual Conditional Expectation
If you want to know more about Individual Conditional Expectation, follow this excellent free book about interpretable machine learning.
Conclusion
A model is interpretable if it can be understood without using post processing techniques. These are simple models in the Provision.io platform. For more complex models, including deep learning models, it is necessary to use additional technical solutions to understand the model, we then speak of explainability. I briefly presented 4 techniques for understanding complex models. If you want to go further in the understanding of interpretable and explainable models, I invite you to read this free book available online which goes much further into the solutions available to improve the understanding of machine learning models. You will see in the next article how Provision.io brings positive solutions to data scientists with simple interpretable models and complex models with solutions of a posteriori explainability.



