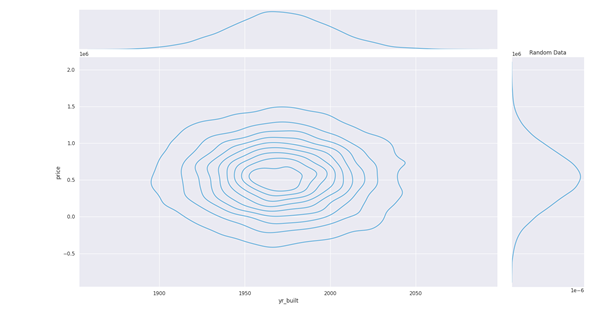
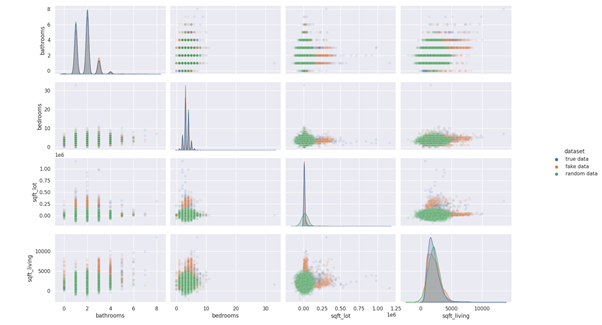
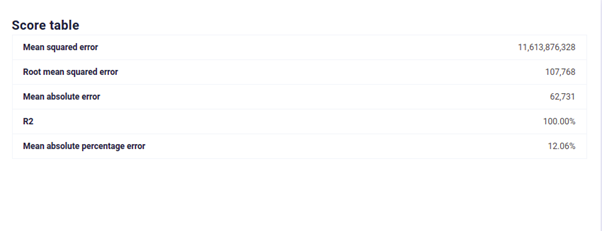
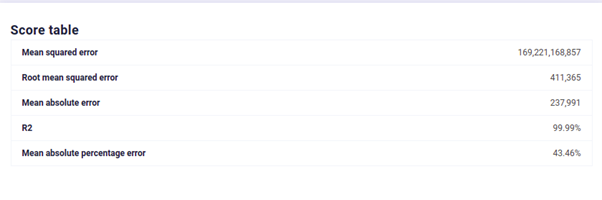
It’s often quoted, “Data is the new oil” and as a data scientist, I clearly know the value of good data to train our model. However, we often face some problems with data:
- Limited or no access because of confidentiality / governance requirements
- Lack of sufficient quantity
- It’s unbalanced and thus leads to biased models
- … the list could go on and on.
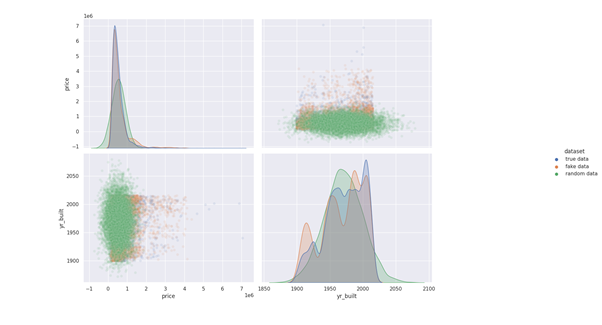
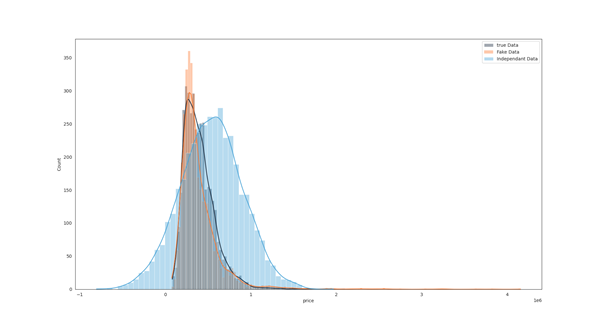
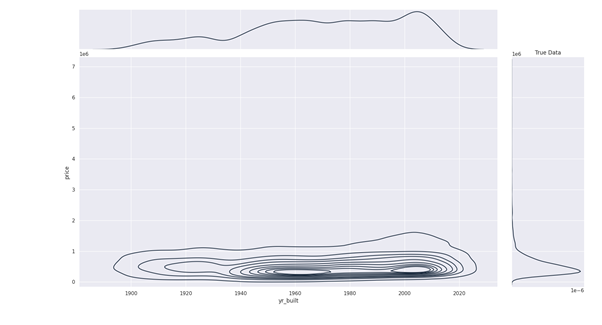
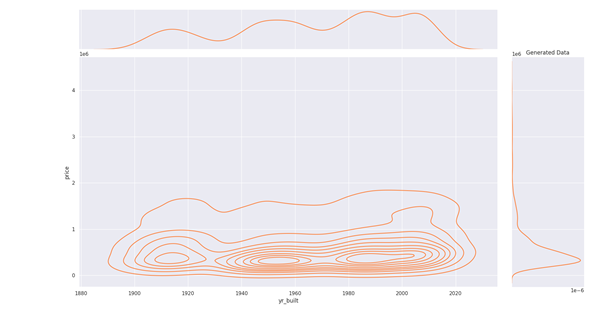
In this guide, we will explore the usage and performance of synthetic data generation. If you want to try it by yourself you can:
Usage of synthetic Data
A common problem in the just about every industry (telecom, banking, healthcare, etc.) is confidentiality of data. We want to build models using sensitive data while avoiding confidential or proprietary information.
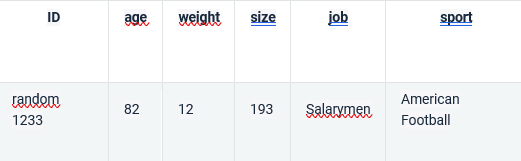
As an example, you may have a dataset in which each row is age, gender, size, weight, place of residence, etc. Even if data is anonymized by removing name or email, it’s often easy to find some particular person through their unique combination of features as in the following example:
A 30 year old man who lives near Cambridge, earns $30000 a month, whose wife is an engineer and subscribes to a sports magazine would be unique enough to know a lot about him, even without identity data. o no.
The second problem is lack of data or worse, a lack of data for some segment of the population that will then be disadvantaged by models.
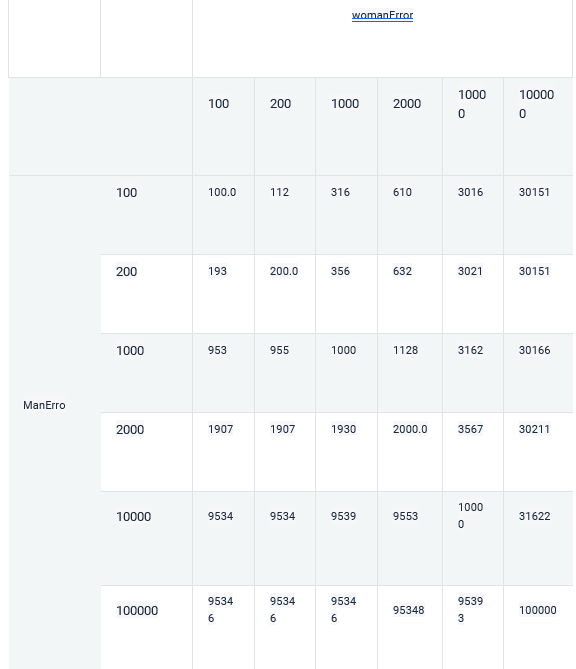
For example, let’s say that we have a dataset with 10000 men and 1000 women and we are using RMSE as the metric for our training. Let’s say for the sake of this article that every prediction for men has the same error manError and women have a womanError constant error.
The Score of a model will be :