
Machine Learning has grown rapidly in popularity over the past ten years. Projects using this technology have been implemented within many kinds of companies, from start-ups to Fortune 500 ones and have hopefully brought a good return on investment (see our article “Can an AI project succeed without delivering any ROI ?”).
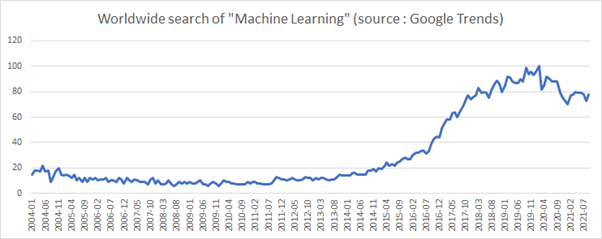
Excel chart showing the evolution of the search of “Machine Learning” according to Google Trends
While a good ROI is a nice benefit, we have to keep in mind that a project that uses Machine Learning is not magic.

While Machine Learning may look magic, a project isn’t only about modelisation
There are many things that Machine Learning does not do. For example, the business problem doesn’t define itself, the algorithm needs to be selected among a plethora of open source offerings, fed with “quality” data, trained using a good metric, optimised, etc. Eventually it will be put into production. All these steps require various personnel, such as business users, data scientists, data engineers, software engineers, devops, and more. In fact, a Machine Learning based project looks like a giant twisting strand of spaghetti that takes time to solve and extract business value from.
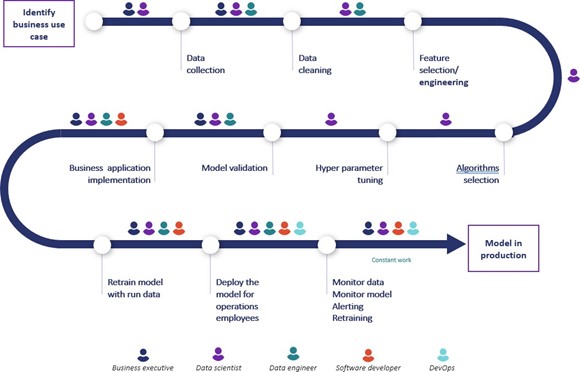
The Machine Learning spaghetti as seen by Provision.io
The high number of steps and people involved in solving the problem will lead to friction and time lost, which translates, at best, to a project with a lower return on investment, or worse, a project that doesn’t work and that won’t make it into production. This is something that happens more often than we care to admit and will discredit Machine Learning capabilities from a business user point of view, alongside validating the feeling that the Data Science team has worked for literally “nothing”. I mean by that, as a Data Scientist myself, I love to see that my work delivers value for my business user and overall for my company.
So how can we remove some of the friction and save time when doing Machine Learning based projects? The solution is something called “AutoML”.
AutoML You Say?
AutoML is a shortcut for Automated Machine Learning (including Deep Learning). It is a process that aims to automate some parts of a Machine Learning process. Generally speaking, most AutoML support (or should support) at least:
- Technical feature engineering (casting your raw dataset into matrices)
- Model evaluation and validation, leading to model selection
- Hyperparameters tuning of promising models
At best, the good ones offer a lot more capabilities, such as :
- Advanced feature engineering (multilingual text & image support)
- Automated data analytics (univariate, bivariate)
- In-depth model understanding (confusion matrix, roc curve, feature importance)
- Feature selection
- Experiment tracking and versioning
- UI complemented with SDKs (in R & Python)
Some of them can even provide what we like to call “MLops” capabilities, especially the ones that offer model deployment and monitoring within a coherent interface. This goes a little bit beyond AutoML and lands more in the “AI Model Management Platform” arena.
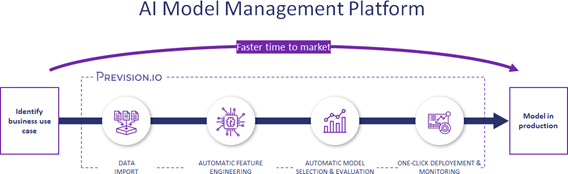
From spaghetti to a more lean process
Why Would AutoML Be a Fit for Me?
As a Data Scientist, our job is to make Data Science work, which means solving real world problems and bringing value to our lines of business. We aren’t paid (or shouldn’t be paid) to spend 3 months tuning a model that won’t even make it into production. We should be efficient and always have one goal in mind, delivering things that have business value.
However, it’s true that to achieve this goal, feature engineering, modelling and hyperparameters optimization should be done. Sure, but do we need to do it by hand every single time? Do we need to code a pipeline that will differ between a linear model and a gradient boosting model only to find after some iterations that we can discard one of the two? Do we need to implement every categorical feature transformation we have in mind in order to understand that in our project only target encoding makes sense? And what about doing it again when we discover that a new data source could be included into our pipelines?
It might look funny when we first start in the Data Science field because we learn from experience (just like Machine Learning models by the way), but after we have acquired some experience and made a couple of projects, we don’t want to spend our precious time on technical tasks that can be automated by some solutions. We want to spend our time focusing on the problem to solve, making sure that the line of business has clearly defined its goal, that the metric chosen is adequate for solving the problem and that we gather the best data we can from our IT department. This is a much more valuable question than asking if our XGBoost should have a depth of 8 or 10 (even if
answering this question has value, don’t get me wrong). It is a better use of time to let an AutoML solve this question for you, while you get what’s needed for the project to work. In the end, you’ll have a project delivered on time, with still very good predictive power (as long as you have selected a good AutoML solution, all aren’t equal).
AutoML Pros and Cons
If we summarize the pros of AutoML, we could think of:
- Accessibility: Experts and those less experienced (think “Citizen Data Scientists”) can work together on the same technical solution, increasing the penetration of AI within the
- Time / cost saving: With the AutoML solution being (wait for it) automated, it makes sense that they’ll lead to results faster than humans can achieve. This will free some of our time to focus on other things and overall lower the cost of the project we’re working
- Modelling performance: Okay, this one is open to discussion. While it is true that Data Science experts can achieve modelling performance of the best AutoML on the market, they’ll take time to achieve it (hence my previous points). Less experienced users will definitely struggle to achieve this level of
- Ease of comparison: Especially true when coupled with experiment tracking capabilities, an AutoML solution will ease the comparison of models, especially if configured the right way. No more hassle remembering which dataset has been used or how the metric has been computed (Hold out? Cross validation (and how it was defined)?) This will also rationalise the number of notebooks, python / R scripts being done during this step that sometimes can look a little bit messy 😅.
- Less pitfalls when modelling: Good AutoML solutions handle some real world issues about data that we may not have addressed as a Data Scientist (new modality of cardinal value popping up after a model is being deployed? Some words that weren’t present in our text corpus that need to be predicted on? Out of range values?) Data Science projects are full of traps, don’t fall into

Data Science project are full of traps, better avoid them
On the flipside, there are some cons of AutoML :
- The “Blackbox” effect: depending on the AutoML solution you use, some of them will typically tell you “hey! Take this model a move away”, without any information on it. This is what we generally call ‘blackbox.’ While it’s sometimes true, state-of-the-art AutoML solutions can provide you complete information about the model selected, its hyperparameters and the feature engineering applied alongside some helpful information about the model behavior which negate the first point (as long as you chose a good AutoML solution 🧐).
- Initial cost: While some AutoML solutions are open source and free to use, the most complete ones are commercial solutions which means you’ll have to pay some fees to access However, the cost of these solutions is rapidly shrinking, especially for the ones that offer the PAYG (“pay as you go”) model. Also, please remember that using AutoML will save you time (see above) and will probably decrease the total cost of ownership of your project even if they require an upfront investment.
- Completeness of use case coverage: Some AutoML solutions only work on nice matrices (so you need to make the feature engineering yourself), some support only tabular data, some include time series capabilities, some text You get the idea. All AutoML solutions aren’t equal in the coverage of use cases. While the most complete ones will help you achieve most of your use case, if you are searching for AutoML working on 4K videos with unsupervised capabilities, you will probably face some issues. Fortunately, most business grade use cases are as of today covered by the well established AutoML solution, especially the commercial ones.
- Computational power: AutoML solutions, like any ML based solution will require computational power in order to work well. This power can be set by your IT or provided by some commercially available solutions that are working in the cloud and will manage the needed infrastructure for you, resolving this
AutoML vs Data Scientist ?
As of today, we often hear the debate around “is AutoML going to signal the death of a Data Scientist” (see here or here)? I would like to end the discussion right now. AutoML isn’t made to replace Data Scientists, and it won’t ever replace them.
The point is that AutoML doesn’t compete with Data Scientists (either Experts or Citizens), they complete themselves. AutoML will take care of the grunt work within the modelling part allowing you to focus on the use case you want to solve, freeing your time to actually improve datasets matching the problem with advanced business features that will lead to a highly accurate model in no time. This will increase the project’s ROI and improve confidence with your business users.



