
This is a part 1 of a 2 part Series focused on Model Selection. Part 1 focuses on Classifier Models. For access to part 2 on Regression Analysi, please <insert link to pleze page>
Part 1 : Classifier models
When trying to tackle a business problem with Machine Learning, you often end up with many models. Yet, in most cases, only one of them is going into Production.
This guide shows you how to evaluate and select your models according to business objectives. If this area is of interest, please link over to a blog my colleague wrote as there should not be any project without defined R.O.I.
The advice contained in the rest of this post applies to most any project, if you could try it by yourself with one of our public standard Dataset and a Provision.io account.
Purpose of a Data Science project
Data science has left the Lab and is now a useful application to improve industrial processes or prevent loss. Yet it sometimes struggles to deliver return on investment.
As most of the Data science processes and tasks are now streamlined thanks to tools and software, it’s now the data scientist’s duty to check that projects actually solve a business problem.
Data science is a set of tools to build predictive models.
A large number of them are supervised models and fall into two categories :
- Classification: you have some data or description of something and the models tells you which category it belongs
- Regression: you have some data and your model tells you in how many days something will break or how many of your items you are going to sell,
First and foremost, any model will make some errors. Evaluating them is knowing how much these errors will cost and comparing it to the gain you get from using this model. If using a model makes you earn $1mm but its errors cost $30k, you should probably go for it.
As obvious as it sounds, if your model’s errors cost you $500k to earn $20k, you’d better not use it.
The cost of an error comes mostly from two things :
- you miss an opportunity and lose
- you take an action that costs more than if you had not done anything (and prevent nothing )
This should be put in regards to the gain from a model that comes from :
- avoiding a loss
- gaining more

Thus, evaluating a model comes down to answering this question :
- How many times will the model make an error on my production data?
- How many errors would I have made without the models or with a random strategy?
- How much does each type or error cost?
Example of missed opportunities
Here are some standard missed opportunities due to model error
Industry | Model | Model type | Error Type | Missed Opportunities |
B2B |
Churn Classifier |
Classifier |
False Negative | The model wrongly predicted some customers as “will not churn”. You do not take any action and lose your customers |
Retail |
Sales Forecasting |
Regression |
Underesti- mation | Your model forecast 90 sales of burgers so you only bought 90 burgers. Yet you could have sold 120 |
Energy |
Consumption Forecast |
Regression |
Underesti- mation | You shut down one power plant sector because you expect only 45Tw of electricity consumption |
Retail |
Recommender system |
Multiclassifi cation |
Class Error | Your recommendation system offers a $34 item to someone who would have bought a $120 item |
B2B2 |
Text Classifier |
NLP |
Class Error | An urgent email from a very important customer goes into the “low priority” bucket |
Example of unnecessary expenses
And here are some errors that make you take action
Industry | Model | Model Type | Error Type | Missed Opportunities |
B2B |
Churn Classifier |
Classifier |
False Positive | The models predict that customer X will churn next week. You call them and offer a discount, but in fact she would have never left. |
Retail |
Sales Forecast |
Regression |
Over Estimation | Your model predicts $10,000 burger sales next week. You stock 10,000 burgers but sell only 5,000. |
Banking |
Fraud Classifier |
Classifier |
False Positive | You reject a transaction because your model tells you it’s fraudulent despite the fact the transaction is legitimate. |
Metrics vs objectives :
Note : you can grab this dataset on our dataset page in order to run a classification, a multi classification and a regression and get the chart used to illustrate this article
- DNS Attacks ( multi classification )
- Sales Forecasting ( Regression )
- Songs Hits ( Classification )
In most Machine Learning tools and frameworks, your models are built with the goal to optimise some defined metrics with specific mathematical properties. So selecting a model should only be a matter of getting the best metrics.
For example, you can rank your model from best metric to worst, look if stability ( variance of the performance across fold ) is good enough and go for the best one.
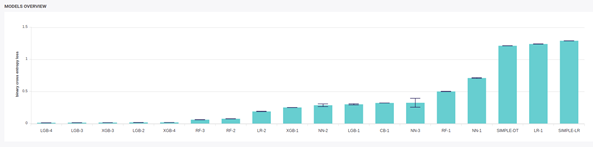
Models performances and variability of a Multi-Classification problem
If you have real time issues, maybe you need to look after the response time of models too and look for the best compromise.
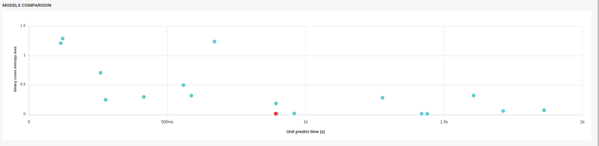
Response time vs performance of models
Yet, depending on the cost of missed opportunities and unnecessary actions, you probably have to compute your own performance metrics to select the fittest model, not the best.
( note : in fact, you could get a metric more aligned with business objective by using appropriate weighting in your dataset )
Here are some rules for putting cost and gain in your data science metrics.
Evaluating your Classifier Models
False positive
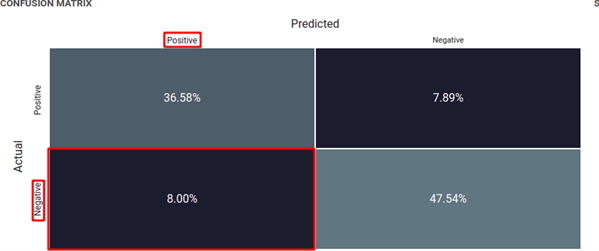
On a Classification, the model tells you something will happen but it does not (It predicts a Positive but actually is Negative ). As a consequence you take some actions that are unnecessary. False positives cost you action for nothing.
False negative
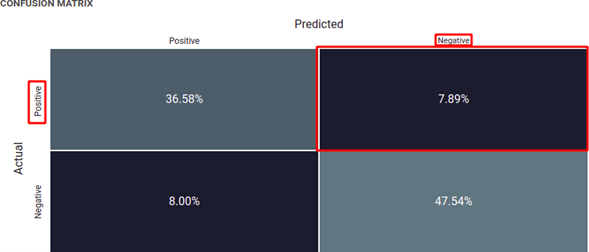
The model misses a prediction and does not alert you (This is a False Negative ). You do not take action and have some loss for not taking action.
By assigning cost to each quadrant of the confusion matrix, you can get the gain ( or cost ) of using your model.
Let’s take an example.
Imagine that you are a music producer and must decide to launch a new artist based on some predictive algorithm.
If the model says “Go for it” and is right, you spend some money but get a huge reward. Let’s say the gain ( income minus expenses) is $1,000,000.
If the model says “Go” but it fails, you lose money as your expenses are greater than your income. Let’s say you lose $400,000( your net gain is -$400 000).
If the model says “Do nothing”, you don’t have any expense and any income. Gain and loss are $0.
You could build this kind of Cost Matrix :
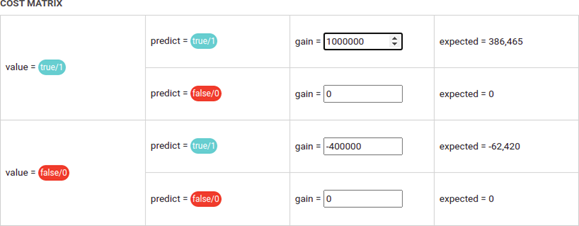
If you use the Confusion Matrix of your model :

You can compute what using your model on 1000 artists will get you :
1000*38.65*$1,000,000 – 1000*15.6*$400,000*1000*5.82*0+1000*39.93*0 = $32,410,000,000
Others Example of Costs Matrix
- you have a model for predictive maintenance. Sending a team for inspection when the model predicts a Positive costs $800. Sending a team prevents a Break down cost $2,000
- All positives, True Positives and False Positives have a “gain” of
-$800. You spend money sending a team but avoid breakdown, even if nothing would have happened
- False Negatives have a “gain” of -$2,000. The model does not alert you, you don’t spend money sending a team but a breakdown
- True Negatives have a gain of You don’t do anything and nothing happens
The Cost Matrix of such a case would be:
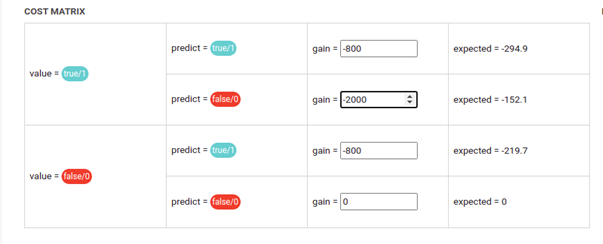
This is a case where you will always lose money but there is optimal negative, where you lose less money
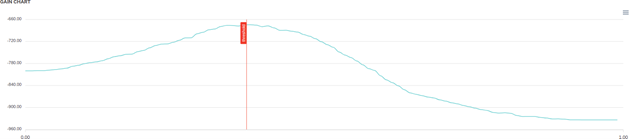
Extract from gain chart in Provision.io modeling tools
You have a sales team that engages customers based on your model
- if the model says to engage, it costs $800
- if you get sales, you earn $2,600 from which you subtract the cost of engaging ($800). The gain of a true positive is $1,800
- the cost of negative prediction (doing nothing ) does not lose or earn anything
The Cost Matrix would be :

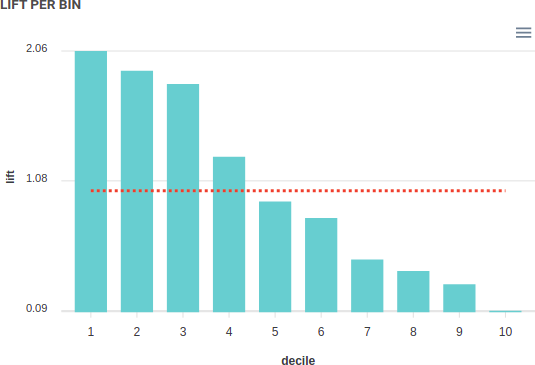
Lift
Lift is a very important concept that any data scientist should understand.
Lift is “how much better is your model than a random decision” and this evaluation is often neglected. Let’s say for example you got some transaction, a credit card transaction or a sale on a shopping website.
Your past 7 years data tell you that one transaction out of 10 (so 10%) is a scam. You decide to block 1,000 transactions out of 100,000 with 2 methods :
- Set A : block 1,000 random transactions pick at random
- Set B : block 1,000 transactions where your models told you “Fraud: True”
In your set A, in average you are getting 100 fraudulent transactions, as the average rate of fraud is 10% and you pick 1,000 transactions randomly
In your set B, if your model is perfect ( which never happens ) you should get 1,000 fraudulent transactions as all the transactions tagged fraudulous by your model are indeed fraudulous.
The ratio of target in your model’s selection upon the ratio of target in a random selection is called “lift”. It shows if your model has understood anything about the problem or just throws out a random prediction.
In the previous example , the lift is 10 as the sample done by using your model has 1O times more fraudulent transaction than a random sample
Remember this: if your model only finds 500 True Positives out of 5,000 samples where target rate is 10%, your model does, in fact, nothing because having picked up 5,000 random samples would have yielded 500 True Positives too.
Lift is very important to evaluate over each quantile of your prediction, as it can tell you the amount of action to engage.
Let’s say that you have 100,000 customers for example. Each monday, a model sends you a list of ranked customers along the probability they subscribe to a new plan (upsell). Your call center costs $50 to call a customer. So calling 100 customers is $5,000 but each time you sell a new plan, you earn $500.
On the global population, a customer has one chance out of ten (10%) to subscribe new plan, so if you just call a bunch of 1,000 random customers, it will cost you 50000$ and you gonna earn :
1,000 prospects * 10% * $500 = $50,000
For a total expense of
1000 peoples * $50 = $50,000
So just dialing a prospect at random serves no purpose. You give $50,000 and get $50,000.
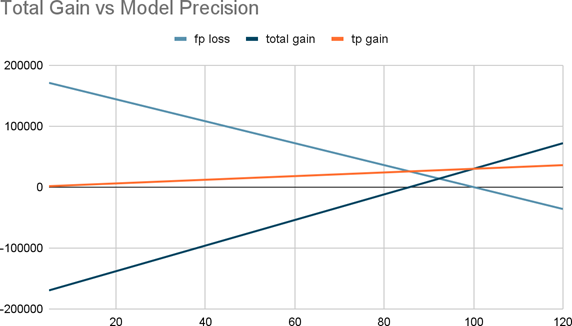
Now let’s say you use a model that ranks your customer according to the probability they subscribe to your new plan and you call them, by bunches of 10,000 (a decile) in the order predicted by your model. The lift decreases from decile to decile as the model is less confident about its predictions. In fact, as the call expenses are stable, there is a point where you should stop calling customers (in the simulation below, you should just call the 40,000’s first customer before starting to lose money)
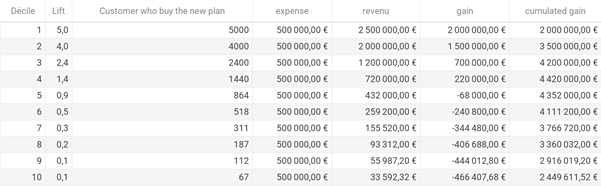
That is what lift is about: taking action on your prediction ranked from highest to lowest and stopping when the actions expected gain becomes negative.
Looking after your model lift by decile could be very useful when you can only engage limited resources (for example, you can make only 10.000 calls a week) as some models may have better global metrics than another but a first decile lift lower, meaning you‘d rather use the one with the higher lift on first decile.
Precision
Is there a way to catch absolutely all fraudulent transactions in a fraud detection model?
Yes.
Block every transaction and you are sure you are getting all the fraudulent ones.
Sure, you blocked a lot of transactions that were perfectly valid, but at least you do not have any more fraud issues.
Of course this is not a good model and the number of true fraudulent transactions you blocked ( True Positive ) divided by all the transactions you blocked ( True positives and False Positives ) is called “Precision”.
For example if you have 100 effective fraudulent transactions out of 500 blocked transactions, your precision is 20%. Defining what is a good precision depends on the cost of your missed opportunities. Of course you should always aim for 100% precision but the cost of your false positives is an important factor.
Let’s say you use a B2B model in telecommunications to prevent fraudulent users from subscribing to a contract, take the expensive smartphone offered and then close their accounts and disappear.
The gain from blocking a fraudulent transaction is the price of the smartphone ( let’s say $300). The cost of blocking a Real Customer is estimated to be its total lifetime value ( given that if blocked, he will never subscribe again to your plan ). Let’s say it’s $1,800 (6 times the gain from blocking a fraudulent transaction )
In that case, it means that if your precision is under 86%, you lose money by using a model.
Recall
Now let’s say that you don’t want to hurt any potential customers by blocking him. How to be sure to never block a true customer ?
Do not block anybody.
You will miss 100% of the fraudulent transactions but won’t have any false positives. The ratio of positive vs total positive is called Recall.
It’s the part of an existing problem that you catch. For example if you catch 400 out of 500 fraudulent transactions, your recall is 80%.
Once again, having a “good recall” depends on the cost of doing nothing vs doing the wrong thing. If doing the wrong thing costs 5 times more than doing nothing, because for example you send a maintenance team where there was no issue, your recall should be at least 80% in order for your model to be profitable.

![[Provision.io R SDK] Apps deployment](../../static/picture/florian-R-6-300x150.jpg)

