
More than ever, Machine Learning pipelines are becoming a central part of AI projects. Tools are flourishing here and there, coming from the open source world or from commercial vendors. But what really is a Machine Learning pipeline? What does it do? How to create one (in an efficient way)? That’s what we are going to talk about.
Machine Learning pipelines
In Machine Learning projects, some steps need to be done in order to have a working solution. Data needs to be gathered, merged, cleaned and analysed. Then typically one or more Machine Learning models are built on top of them, hopefully being then deployed and fed with new data for prediction purposes. At production level, all steps need to be clearly identified and should be reproducible. Pipelines will help you to achieve this goal.
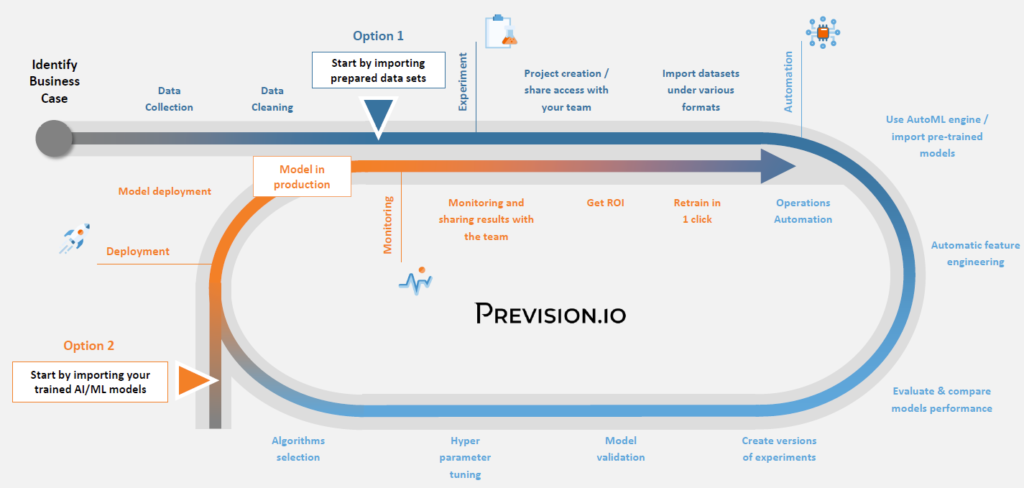
Typical Machine Learning project lifecycle
Pipelines generally come to mind when you need to redo the value process from data ingestion to model building & deployment. However, anything from bulk prediction or model retrained could be “pipelinized” and scheduled.
Right now, most of the well known ML pipelines capabilities are truly coming from the open source world. Unfortunately, they aren’t well packaged and need the user to have more than basic Data Science skills. In fact, they are more focused on IT people like Data Engineers and ML Engineers. Wouldn’t it be better if pipelines were available to a broader audience?
Introducing Provision.io pipelines
At the heart of Provision.io’s offering, automation is one of our pillars. This one contains pipeline creation, execution and monitoring capabilities. It will help your team to quickly create pipelines with a visual editor. This will remove any technical barrier to getting started, but we will still include custom code capabilities that can be written for the most advanced transformations.
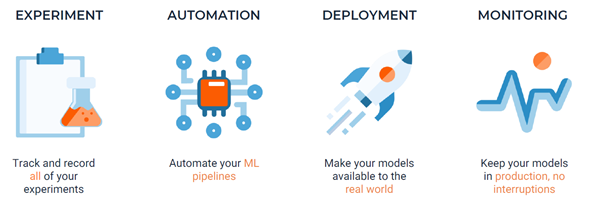
Provision.io’s pillars, automation is the one talking about ML pipelines
Pipelines from Provision.io are meant to be modular in order to fit all your needs and avoid redundancy, hence we divided them into 3 sub categories:
- Pipeline components: low level / atomic operation
- Pipeline templates: template of multiple chained pipeline components
- Pipeline run: an instance of a pipeline template that can be scheduled, executed multiple times and monitored
Pipeline components
A pipeline component is a low level operation that can be applied to existing Provision.io resources (datasets, models, deployments…) Some of them are already built by Provision.io, but you are free to create your own custom pipeline components in your favorite language.
Provision.io pipeline components
The Provision.io platform includes a library of already built pipeline components. They can be seen directly in the UI in Pipelines > Pipelines components
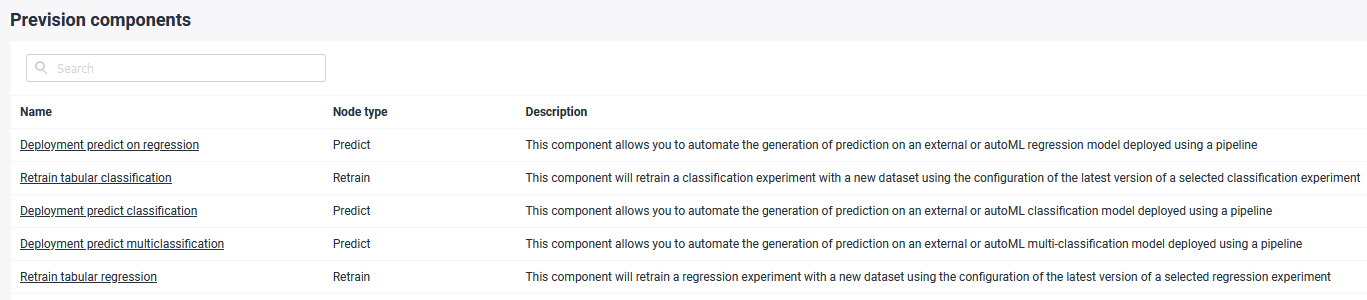
Example of some pipeline components already built by Provision.io
Most of them belong to one of the following categories:
- Retrain of an experiment
- Prediction of a deployed experiment
- Dataset read / write operation
- Dataset basic transformation (filter outliers, sample…)
- Dataset feature augmentation (add weather feature, add special days information…)
Note that for the latter, some requirements are needed and are explained in the description of the component of your choice.
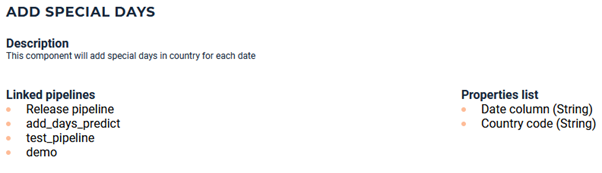
This component will add special days depending of a country code and a date column
Custom pipeline components
While pre-built components from Provision.io are a must-have and will definitely simplify your data science journey, they may be insufficient for more advanced projects. For instance, you may want to do some advanced feature engineering or use your own prebuilt word embeddings based on an external corpus… To do it, you will have to create your custom components and we’ve got you covered here!
To accomplish this, we have a github public repository with resources aimed at ease of custom component creation for python coders.
The general idea is that you have to create a repository (github or gitlab) and submit your component code in it alongside the yaml & docker configuration file (please check the readme from our public repository). Then, you can import your custom component as seen here:
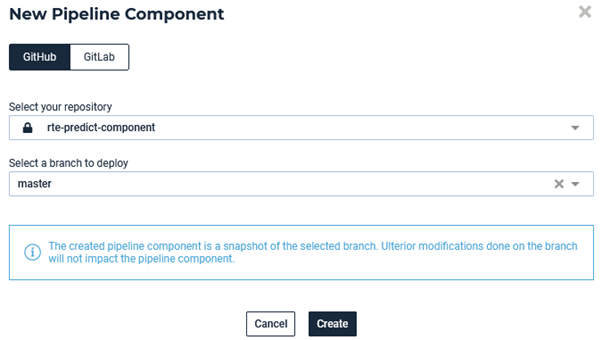
Importing a new custom component from UI
Note that this operation can take some time depending on the requirements’ list you have in your repository.
Pipelines templates
Pipelines templates are a succession of pipeline components chained together. The idea is that you can make multiple operations, either coming from Provision.io components or custom components in order to make a template that fully meets your needs.
In order to create a template, go to the Pipelines > Pipelines templates screen and create a new empty template. After that, locate the “+” button and start customizing your template.

Default empty template

List of node that you can add after clicking the “+” icon
Then you can add a node that fits your needs, including:
- Import → import datasets, already present in your Provision.io environment or coming from data sources
- Export → export datasets to your Provision.io environment or in external data sources
- io components → various components provided by Provision.io (sample, data augmentation, outlier filtering, …)
- Custom components → your own previously imported components
- Predict → prediction on a deployed experiment (so make sure to actually deploy an experiment before using this 🙂 )
- Retrain → retrain an experiment, this will automatically create a new version of it
Here is what I decided to do (which is fairly basic for this example):
- Import a dataset already present into Provision.io
- Launch a prediction on a deployed experiment
- Export results as a data set directly into my Provision.io environment
As you can see, the template is pretty simple and generic since we haven’t specified which dataset to import or which experiment to predict on. That means that it can be used in multiple “pipeline runs” (in which we can instantiate our template).
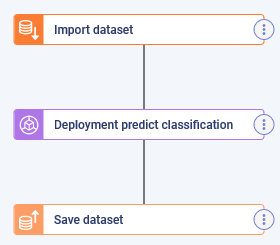
Template importing a dataset, sending it into a deployed experiment and saving results
Of course, you are free to make this template more complex and why not code your own custom component in the middle that can retrieve real time data or make advanced feature engineering…
Pipeline runs
Since we have (at least) one pipeline template ready to go, we can now create a run on top of it.
A pipeline run is just an instance of a template, which is configured (= all nodes requiring parameters will be filled) and that can be scheduled on a regular basis or just launched manually, at your convenience.
Then fill in the information as requested. The most important is filling the template that will be used each time the run is launched.
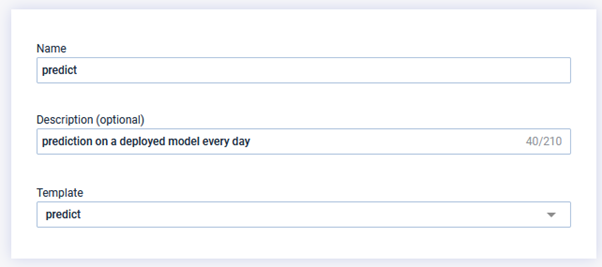
Input the template previously created in the run definition
You are almost done! All you need to do here is fill in the parameters of nodes (if required)
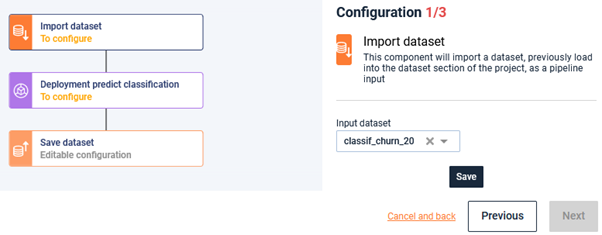
Here, indicate that you want to load the “valid” dataset. Don’t forget to save changes 😉
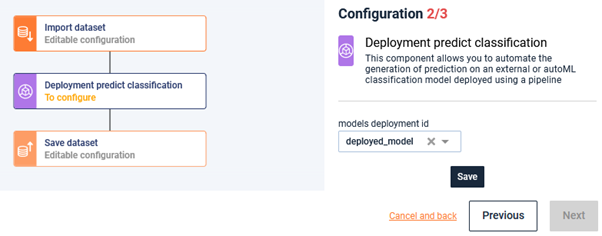
Here, indicate the deployment of your model and hit the save button.
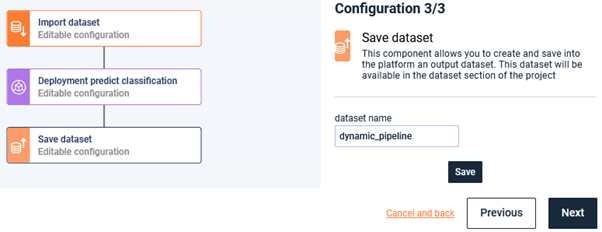
Finally, name the output
The last step consists of choosing the trigger method of your run, including:
- Manual trigger whenever you want
- Periodic trigger at a fixed time (hourly, daily, weekly, …)
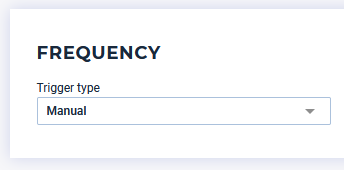
Manual trigger
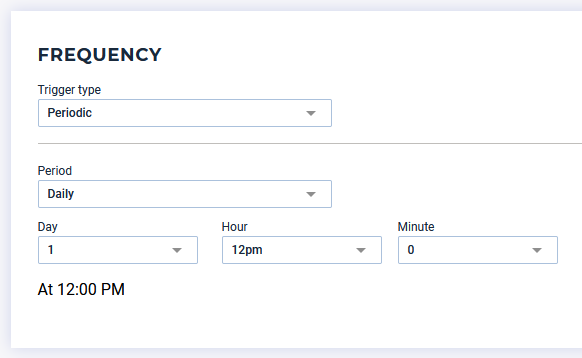
Periodic trigger
By clicking on the name of the scheduled run, you can list every run done and access logs or even trigger a new run manually. Furthermore, if you want to understand typically why an execution has failed, you can access logs and see which step went wrong.
All that being said, I hope you are convinced that pipelines are one of the core features of any production level project and that it shouldn’t be that hard to have them working for you. But don’t take my word for it, register to Provision.io and build your own pipeline in no time! Click here to try it for your self.



